
Học máy (Machine Learning – ML), một nhánh của trí tuệ nhân tạo (AI) và khoa học máy tính, đang ngày càng trở nên phổ biến trong thời đại kỹ thuật số. Sự phát triển chóng mặt của các thiết bị hiện đại, nhu cầu xử lý dữ liệu khổng lồ, và mong muốn tự động hóa các quy trình phức tạp đã thúc đẩy sự ứng dụng rộng rãi của ML trong nhiều lĩnh vực khác nhau. Vậy, Machine Learning là gì? Và nó hoạt động như thế nào?
Machine Learning là gì?
Machine Learning, hay còn gọi là học máy, tập trung vào việc xây dựng các hệ thống có khả năng “học” từ dữ liệu mà không cần được lập trình cụ thể. Thay vì dựa trên các quy tắc được lập trình sẵn, các hệ thống ML sử dụng thuật toán để tìm hiểu các mẫu, quy luật từ dữ liệu đầu vào và tự động cải thiện độ chính xác trong việc đưa ra dự đoán hoặc quyết định. Quá trình này mô phỏng cách con người học hỏi và thích nghi với môi trường xung quanh. IBM, với lịch sử lâu đời trong ngành, đã đóng góp đáng kể cho sự phát triển của ML. Arthur Samuel, một nhà nghiên cứu tại IBM, được coi là người đặt ra thuật ngữ “Machine Learning” thông qua nghiên cứu về trò chơi cờ caro. Một cột mốc đáng chú ý là vào năm 1962, máy tính IBM 7094 đã đánh bại Robert Nealey, một kiện tướng cờ caro, trong một trận đấu.
Machine Learning hoạt động dựa trên nhiều thuật toán khác nhau, nhưng nhìn chung, có thể chia thành hai loại bài toán chính: phân loại (classification) và dự đoán (prediction). Phân loại bao gồm các tác vụ như nhận diện đồ vật, màu sắc, chữ viết, trong khi dự đoán tập trung vào việc ước tính các giá trị liên tục như giá nhà, giá xe, v.v. Mặc dù chỉ là một nhánh của AI, Machine Learning đang trở thành một công cụ không thể thiếu trong sự phát triển của lĩnh vực này. Nó tận dụng các thuật toán, phương pháp thống kê và kỹ thuật phân tích dữ liệu để cung cấp thông tin chi tiết và tác động đến chỉ số tăng trưởng chính của các doanh nghiệp.

Quy trình làm việc của Machine Learning (Machine Learning Workflow)
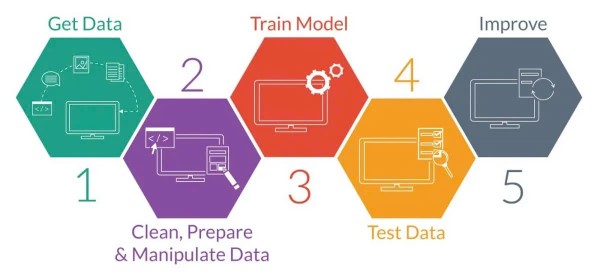
Hiểu rõ quy trình làm việc của Machine Learning là rất quan trọng để áp dụng công nghệ này hiệu quả. Quy trình thường bao gồm 5 bước chính:
Bước 1: Thu thập dữ liệu (Data Collection or Gathering Data)
Đây là bước quan trọng nhất, thường chiếm từ 70% đến 80% tổng thời gian. Chất lượng dữ liệu thu thập có ảnh hưởng trực tiếp đến hiệu quả của mô hình. Việc nghiên cứu, sàng lọc và lựa chọn dữ liệu phù hợp là rất cần thiết.
Bước 2: Xử lý dữ liệu (Data Processing)
Bước này bao gồm các công việc như làm sạch dữ liệu, loại bỏ thuộc tính dư thừa, mã hóa và thu gọn dữ liệu để chuẩn bị cho quá trình huấn luyện mô hình.
Bước 3: Huấn luyện mô hình (Training Model)
Mô hình ML được huấn luyện bằng dữ liệu đã được xử lý. Quá trình này giúp mô hình học hỏi các mẫu và quy luật từ dữ liệu.
Bước 4: Đánh giá mô hình (Evaluating Model)
Sau khi huấn luyện, mô hình được đánh giá dựa trên khả năng dự đoán hoặc phân loại trên tập dữ liệu kiểm tra (test data). Một mô hình tốt thường đạt độ chính xác từ 80% trở lên.
Bước 5: Cải thiện mô hình (Improve)
Dựa trên kết quả đánh giá, mô hình có thể được điều chỉnh và huấn luyện lại để cải thiện hiệu suất. Các bước 3, 4 và 5 thường chiếm khoảng 30% thời gian.
Các khái niệm cơ bản của Machine Learning
Để hiểu rõ hơn về Machine Learning, cần nắm vững một số khái niệm cơ bản:
- Data Set (Tập dữ liệu): Một tập hợp lớn các điểm dữ liệu (data point). Đây là dữ liệu thô được thu thập ở bước 1.
- Data Point (Điểm dữ liệu): Một đơn vị thông tin độc lập trong tập dữ liệu. Ví dụ, trong tập dữ liệu về nhà đất, một điểm dữ liệu có thể bao gồm giá nhà, diện tích, năm xây dựng, v.v.
- Training Data (Dữ liệu huấn luyện) và Test Data (Dữ liệu kiểm tra): Dữ liệu huấn luyện được sử dụng để huấn luyện mô hình, trong khi dữ liệu kiểm tra được sử dụng để đánh giá hiệu suất của mô hình đã được huấn luyện.
- Feature vector (Vector đặc trưng): Một vector đại diện cho một điểm dữ liệu trong tập dữ liệu. Mỗi chiều của vector thể hiện một đặc trưng của điểm dữ liệu. Các mô hình ML thường chỉ có thể hoạt động với dữ liệu dưới dạng vector đặc trưng.
- Model (Mô hình): Mô hình ML được sử dụng để huấn luyện và đưa ra dự đoán.

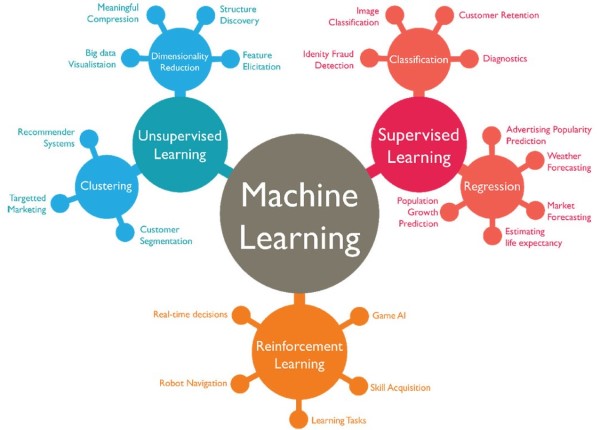
Phân loại Machine Learning
Machine Learning được chia thành ba loại chính:
Supervised Machine Learning (Học máy có giám sát)
Mô hình được huấn luyện trên dữ liệu đã được gắn nhãn (labelled data). Mô hình học cách ánh xạ giữa đầu vào và đầu ra đã biết để dự đoán kết quả cho dữ liệu mới. Các phương pháp phổ biến bao gồm Naive Bayes, hồi quy logistic, SVM, và mạng nơ-ron. Ví dụ: Phân loại thư rác.
Unsupervised Machine Learning (Học máy không giám sát)
Mô hình được huấn luyện trên dữ liệu không được gắn nhãn. Mô hình tìm kiếm các mẫu và cấu trúc ẩn trong dữ liệu. Các phương pháp phổ biến bao gồm phân cụm K-means, phân tích thành phần chính (PCA). Ví dụ: Phân cụm khách hàng.
Semi-supervised Learning (Học máy bán giám sát)
Mô hình được huấn luyện trên một tập hợp nhỏ dữ liệu có nhãn và một tập hợp lớn dữ liệu không có nhãn. Đây là sự kết hợp giữa supervised và unsupervised learning.
Các thuật toán phổ biến trong Machine Learning
Dưới đây là một số thuật toán được biết đến và sử dụng rộng rãi trong Machine Learning:
- Linear Regression (Hồi quy tuyến tính): Dùng để dự đoán giá trị liên tục dựa trên mối quan hệ tuyến tính giữa biến phụ thuộc và biến độc lập.
- Logistic Regression (Hồi quy logistic): Dùng để dự đoán giá trị rời rạc (thường là nhị phân).
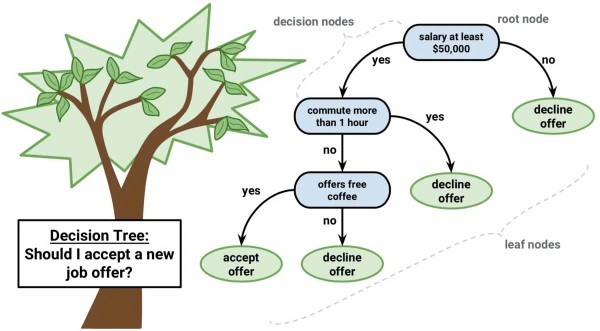
- Decision Tree (Cây quyết định): Một mô hình phân loại hoặc hồi quy dựa trên cấu trúc cây.
- Naive Bayes: Một bộ phân loại dựa trên định lý Bayes, giả định tính độc lập giữa các thuộc tính.
- K-Means: Một thuật toán phân cụm không giám sát.
- Support Vector Machine (SVM): Một thuật toán phân loại dựa trên việc tìm kiếm siêu phẳng tối ưu để phân tách dữ liệu.
- K-Nearest Neighbors (KNN): Một thuật toán phân loại hoặc hồi quy dựa trên khoảng cách đến các điểm dữ liệu lân cận.
- Random Forest: Một tập hợp các cây quyết định, cải thiện độ chính xác dự đoán.
- Gradient Boosting và AdaBoosting: Các thuật toán boosting, kết hợp nhiều mô hình yếu để tạo ra mô hình mạnh.
- Dimensionality Reduction (Giảm chiều): Các kỹ thuật giảm số lượng thuộc tính trong dữ liệu mà vẫn giữ lại thông tin quan trọng.
Ứng dụng thực tiễn của Machine Learning
Machine Learning đang được ứng dụng rộng rãi trong nhiều lĩnh vực, bao gồm:
- Ngành y tế: Chẩn đoán bệnh, phát hiện ung thư, cá nhân hóa điều trị.
- Tài chính: Phát hiện gian lận, đánh giá rủi ro tín dụng, dự báo thị trường chứng khoán.
- Marketing: Phân khúc khách hàng, cá nhân hóa quảng cáo, dự báo doanh số.
- An ninh: Nhận diện khuôn mặt, phát hiện sự kiện bất thường, an ninh mạng.
- Giao thông: Xe tự lái, tối ưu hóa giao thông.
- Sản xuất: Dự báo lỗi máy móc, tối ưu hóa quy trình sản xuất.
- Nông nghiệp: Dự báo năng suất cây trồng, quản lý chất lượng sản phẩm.
Ví dụ, trong dự báo thời tiết, Machine Learning giúp phân tích một lượng dữ liệu khổng lồ về các yếu tố khí tượng để đưa ra dự báo chính xác hơn so với phương pháp truyền thống.

Câu hỏi thường gặp
Hãy cho một số ví dụ về ứng dụng của Machine Learning?
Một số ví dụ gồm: nhận dạng giọng nói, chẩn đoán y tế, phân tích dữ liệu và trích xuất thông tin, nhận diện hình ảnh, đề xuất sản phẩm, dự báo thời tiết, v.v.
Giữa AI và Machine Learning có sự khác biệt nào?
AI là lĩnh vực rộng hơn, bao gồm nhiều kỹ thuật khác nhau để tạo ra hệ thống thông minh. ML là một nhánh của AI, tập trung vào việc cho máy tính học hỏi từ dữ liệu.
Học Machine Learning có khó không?
Học ML đòi hỏi sự kiên trì và nỗ lực vì nó liên quan đến nhiều kiến thức toán học và lập trình. Tuy nhiên, với nhiều tài nguyên học tập hiện có, việc tiếp cận và học hỏi ML đang trở nên dễ dàng hơn.
Tóm lại
Machine Learning là một lĩnh vực mạnh mẽ và đang phát triển nhanh chóng, với nhiều ứng dụng thực tiễn trong đời sống hiện đại. Hiểu rõ về các khái niệm, thuật toán và quy trình làm việc của ML là chìa khóa để tận dụng sức mạnh của công nghệ này.




